开yun体育网“龙虾大模子排行榜”-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
往日两年,AI 圈盘问最多的一件事,其实很粗造:哪个模子更灵巧。 谁的推理更强,谁的磨砺分数更高,谁又刷新了哪个榜单。 但到了 2026 年,全球不太温雅谁更灵巧了,反而初始问一个更试验的问题:哪个模子更会干活? 跟着 OpenClaw 这类 Agent 框架初始爆火,越来越多建筑者不再仅仅和 AI 聊天,而是让大模子真谨慎受任务。 写代码、查尊府、惩办邮件、整理文献、调用 API,以致我方拆解复杂经由,一步一步把事情作念完。 在建筑者圈子里,这事还有个高出形象的说法:养龙虾。 把模子接进 A
-

往日两年,AI 圈盘问最多的一件事,其实很粗造:哪个模子更灵巧。
谁的推理更强,谁的磨砺分数更高,谁又刷新了哪个榜单。
但到了 2026 年,全球不太温雅谁更灵巧了,反而初始问一个更试验的问题:哪个模子更会干活?
跟着 OpenClaw 这类 Agent 框架初始爆火,越来越多建筑者不再仅仅和 AI 聊天,而是让大模子真谨慎受任务。
写代码、查尊府、惩办邮件、整理文献、调用 API,以致我方拆解复杂经由,一步一步把事情作念完。
在建筑者圈子里,这事还有个高出形象的说法:养龙虾。
把模子接进 Agent 框架,就像往水箱里放一只龙虾,让它我方在内部跑任务、调器具、折腾责任流,看它到底能弗成把活干理会。
那到底哪款大模子,最相宜拿来“养龙虾”?
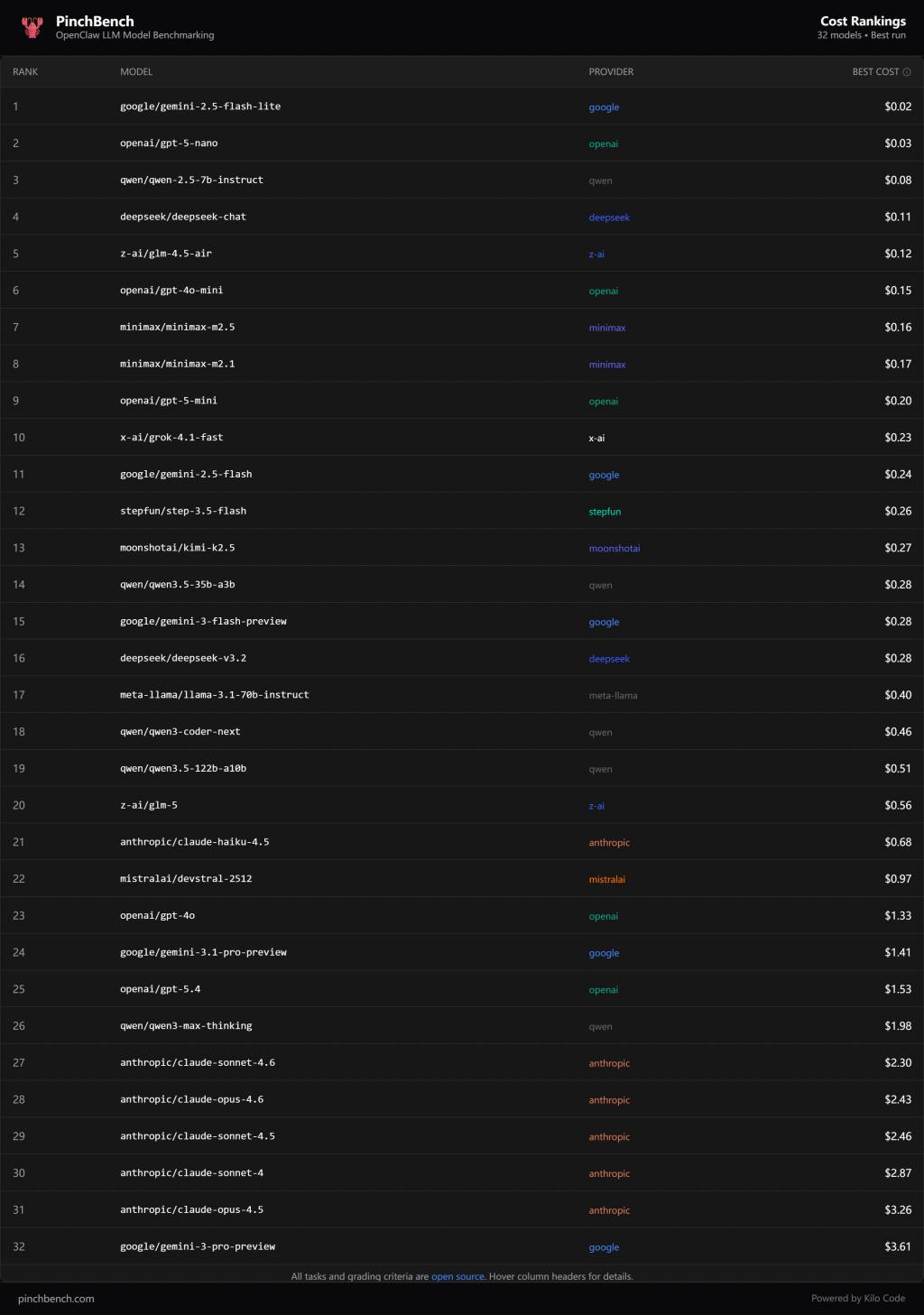
最近,OpenClaw 首创东谈主 Peter Steinberger 发布了一份名为 PinchBench 的基准测试榜单。
连气儿实测了 32 个主流大模子,从收遵守、速率和老本三个维度作念了圆善对比。
这也成了目下第一份挑升针对 Agent 任务的,“龙虾大模子排行榜”。
而榜单一出来,许多东谈主第一响应皆是:这排名,大略有点出乎预料。
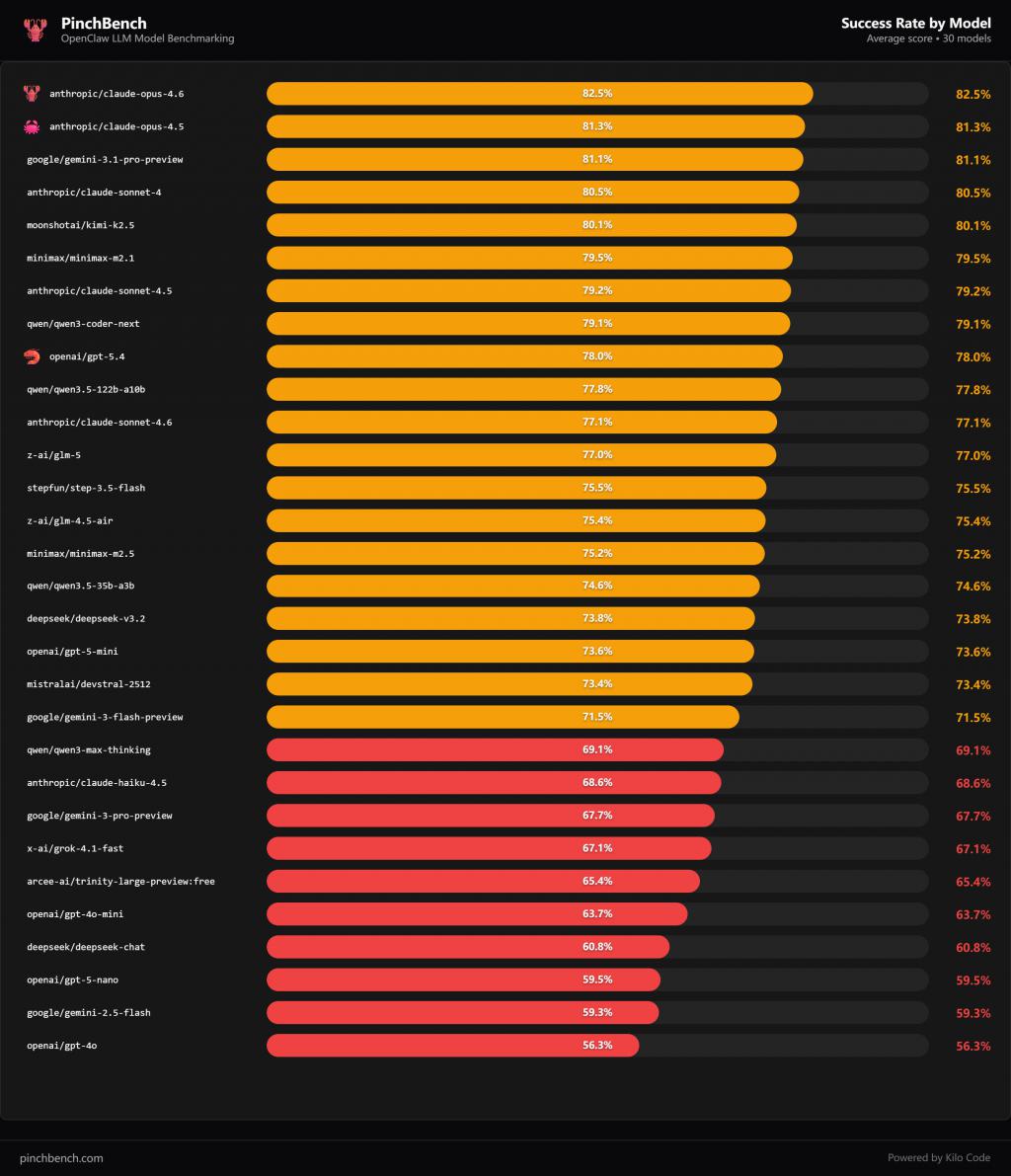
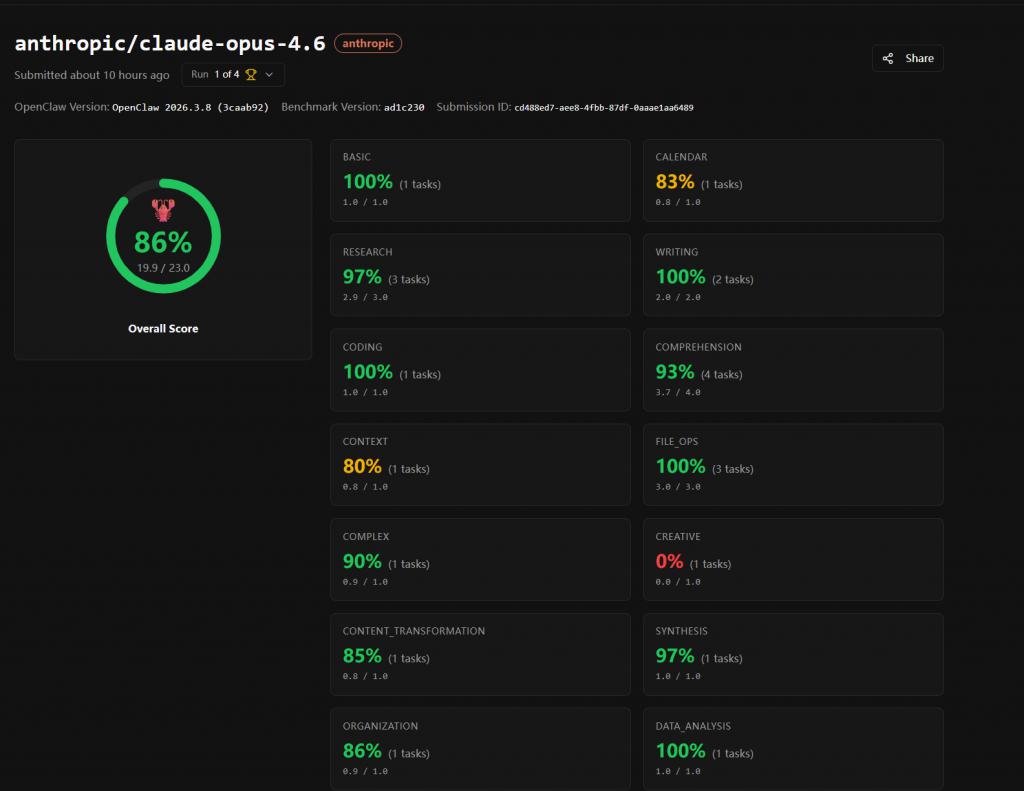
从收遵守来看,榜单第别称并不是全球常提到的“新模子”,而是 Anthropic 的旗舰模子 Claude Opus 4.6。
它在 PinchBench 里的任务收遵守达到了 82.5%。
紧随自后的,是 Claude Opus 4.5,收遵守 81.3%。第三名则是谷歌的 Gemini 3.1 Pro Preview,收遵守 81.1%。
前三名基本皆处在 80% 以上的收遵守区间,差距十分小。
但更有酷爱的是接下来的排名,第四名是 Claude Sonnet 4,收遵守 80.5%。
第五名则是国产模子 Kimi K2.5,收遵守 80.1%。第六名是另一款国产模子 MiniMax M2.1,收遵守 79.5%。
换句话说,在最中枢的收遵守见地里,国产模子仍是稳稳插足第一梯队。
但有些模子的排名就有点出东谈主料到了。举例 OpenAI 的新模子 GPT-5.4,收遵守只消 78%,排在榜单第九。
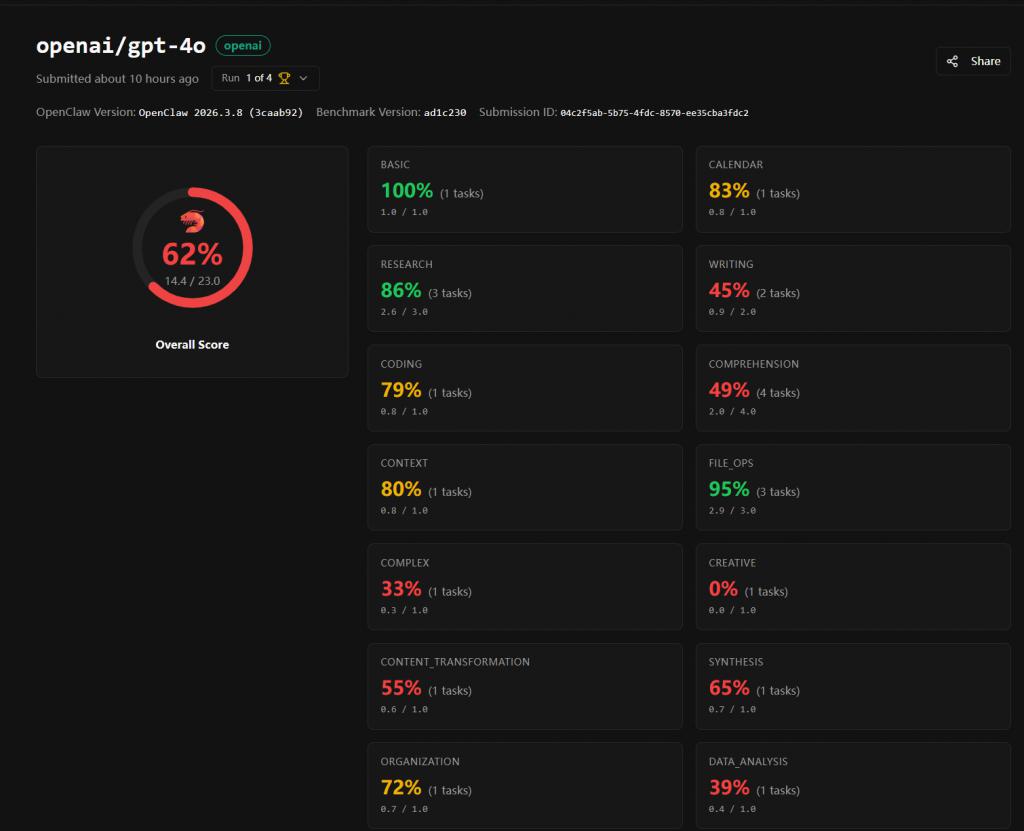
而不少建筑者平庸俗用的 GPT-4o,收遵守以致只消 56.3%,排在榜单倒数。
这其实证据了一件很难题的事情:传统的大模子排行榜,并弗成很好展望 AI 在 Agent 任务里的阐明。
往日许多榜单实质上是“磨砺方式”,比如常识问答、数学推理、代码题,只消模子给出正确谜底就算完成任务。
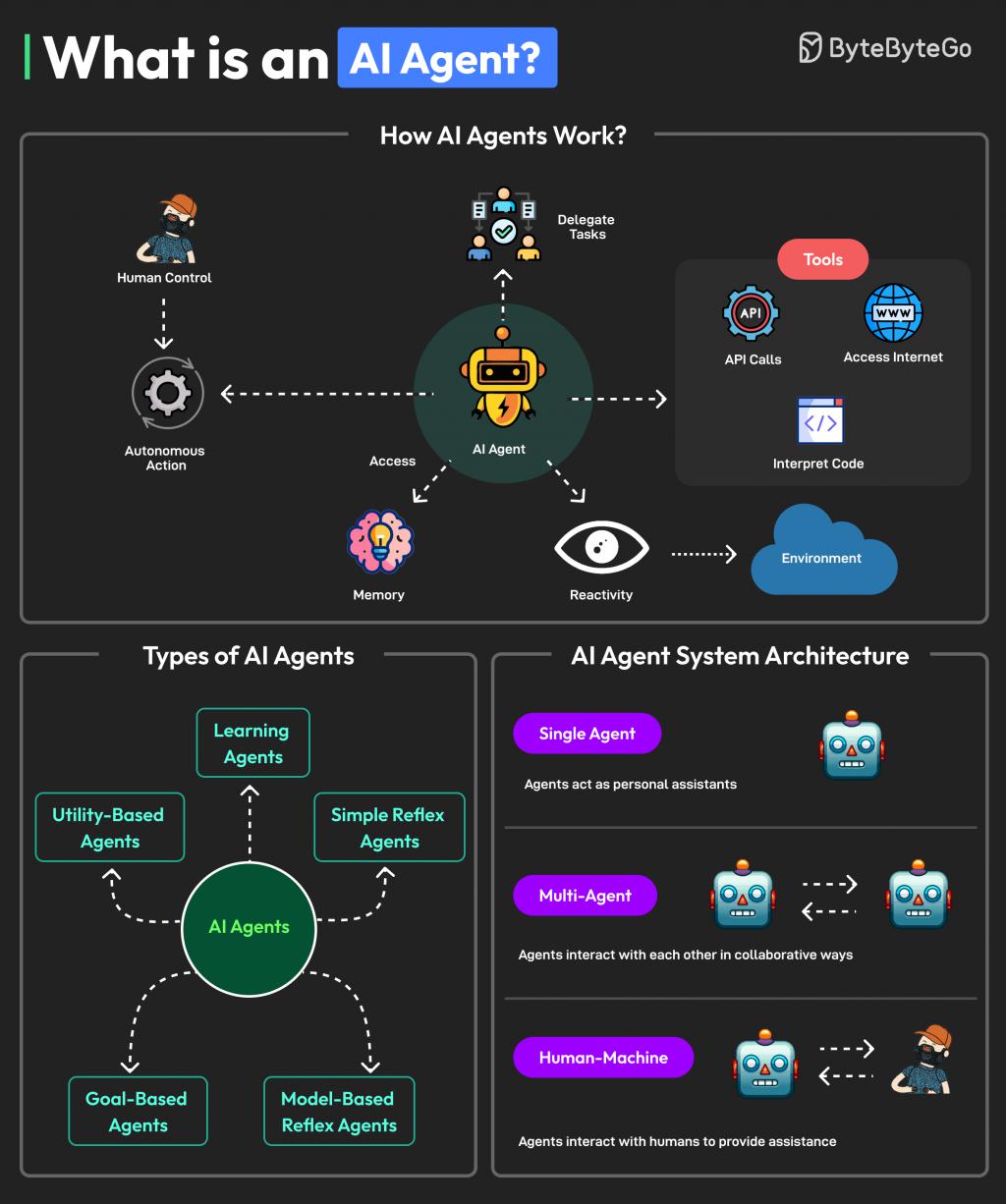
但在 Agent 系统里,AI 要作念的事情彻底不同,它不仅要领略提示,还要我方拆革职务、调用器具、读取文献、生成中间成果、实施多手脚操作。
若是中间任何一步出错,所有这个词这个词任务就可能失败。
换句话说,Agent 任务测试的不是模子“会不会答题”,而是它能弗成简直像一个数字职工相同把事情一步一步作念完。
从 PinchBench 的成果来看,还有一个十分显着的趋势:在 Agent 场景里,模子越大并不一定越好。
许多中型模子反而更褂讪,因为它们推理速率更快、想考旅途更短,在多手脚责任流中难题易“迷途”。
比如排名靠前的 Claude Sonnet 4 和 MiniMax M2.1,其实皆不是各家公司体量最大的模子版块,但在确凿任务中阐明十分稳。
这也意味着大模子正在出现一种新的单干:旗舰模子认真展示极限能力,而中型模子初始承担真确的出产任务。
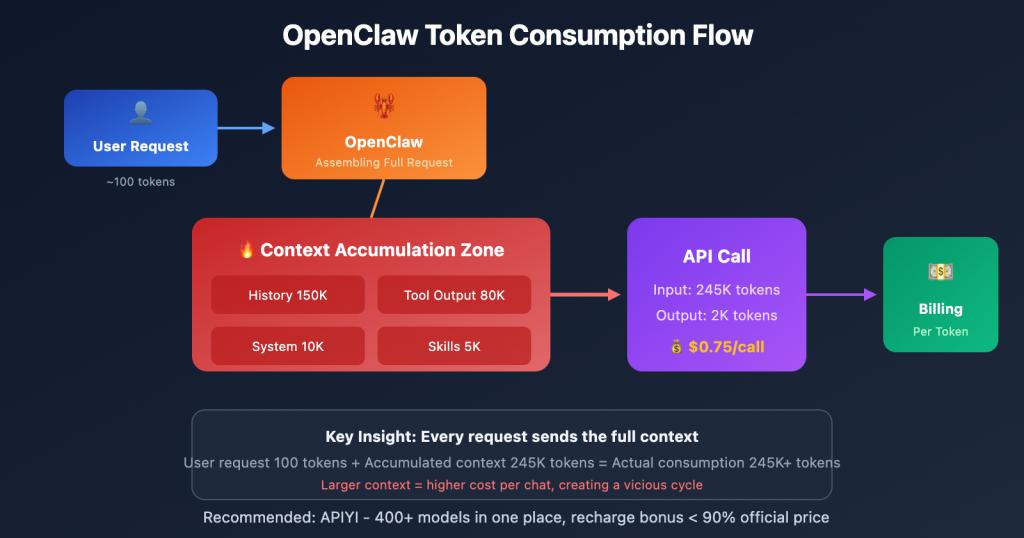
虽然,说到养龙虾,还有一个所有这个词建筑者皆绕不开的问题“老本”。
因为 Agent 系统远比泛泛聊天更烧 Token,模子需要反复想考、生成中间手脚、调用器具,一次圆善任务的 Token 亏本可能是泛泛对话的几倍以致十几倍。
之前在一次 OpenClaw 建筑者约会上,就有东谈主共享过我方的使用账单:每个蟾光 Token 用度就要 1000 到 2000 好意思元,还有一位更夸张的玩家每天亏本 10 亿 Token。
是以目下建筑者圈里流行一句打妙语:安设 OpenClaw 很低廉,养龙虾很贵。
不外说到底,PinchBench 这份榜单最大的价值,其实也不仅仅排个排名。
它便是是第一次比拟系统地复兴了一个 Agent 时期很试验的问题:当 AI 简直初始出来打工了开yun体育网,咱们到底该给它配哪种“大脑”?